1. 미디어파이프 pose
- 미디어파이프(Mediapipe) 포즈 모델이 무엇인지 이해하고, 이를 활용해 사람의 움직임을 추적하는 방법을 배워 봅시다.
- 간단한 실습을 통해 미디어파이프 포즈 모델을 직접 체험 해보도록 합시다.
2. 미디어파이프란 무엇인가요?
- **미디어파이프(Mediapipe)**는 구글에서 개발한 컴퓨터 비전 라이브러리입니다. 다양한 사람의 움직임을 감지하고 추적하는 기능을 제공합니다.
- 예를 들어, 손가락의 움직임을 추적하거나 얼굴의 표정을 감지할 수 있으며, 우리가 오늘 배울 포즈(몸의 자세) 추적도 가능합니다.
https://ai.google.dev/edge/mediapipe/solutions/studio?hl=ko
MediaPipe 스튜디오 | Google AI Edge | Google AI for Developers
LiteRT 소개: 온디바이스 AI를 위한 Google의 고성능 런타임(이전 명칭: TensorFlow Lite)입니다. 이 페이지는 Cloud Translation API를 통해 번역되었습니다. 의견 보내기 MediaPipe 스튜디오 컬렉션을 사용해 정
ai.google.dev
미디어 파이프 스튜디오
3. 포즈 모델이란?
- 포즈 모델은 사람의 신체를 인식하고 추적하여, 신체의 중요한 부분들을 인식하는 모델입니다.
- 예를 들어, 어깨, 팔꿈치, 손목, 무릎, 발목과 같은 신체의 주요 지점을 **랜드마크(landmark)**라고 부릅니다.
- 이러한 랜드마크를 추적하면 사람이 어떻게 움직이고 있는지, 어떤 자세를 취하고 있는지 알 수 있습니다.
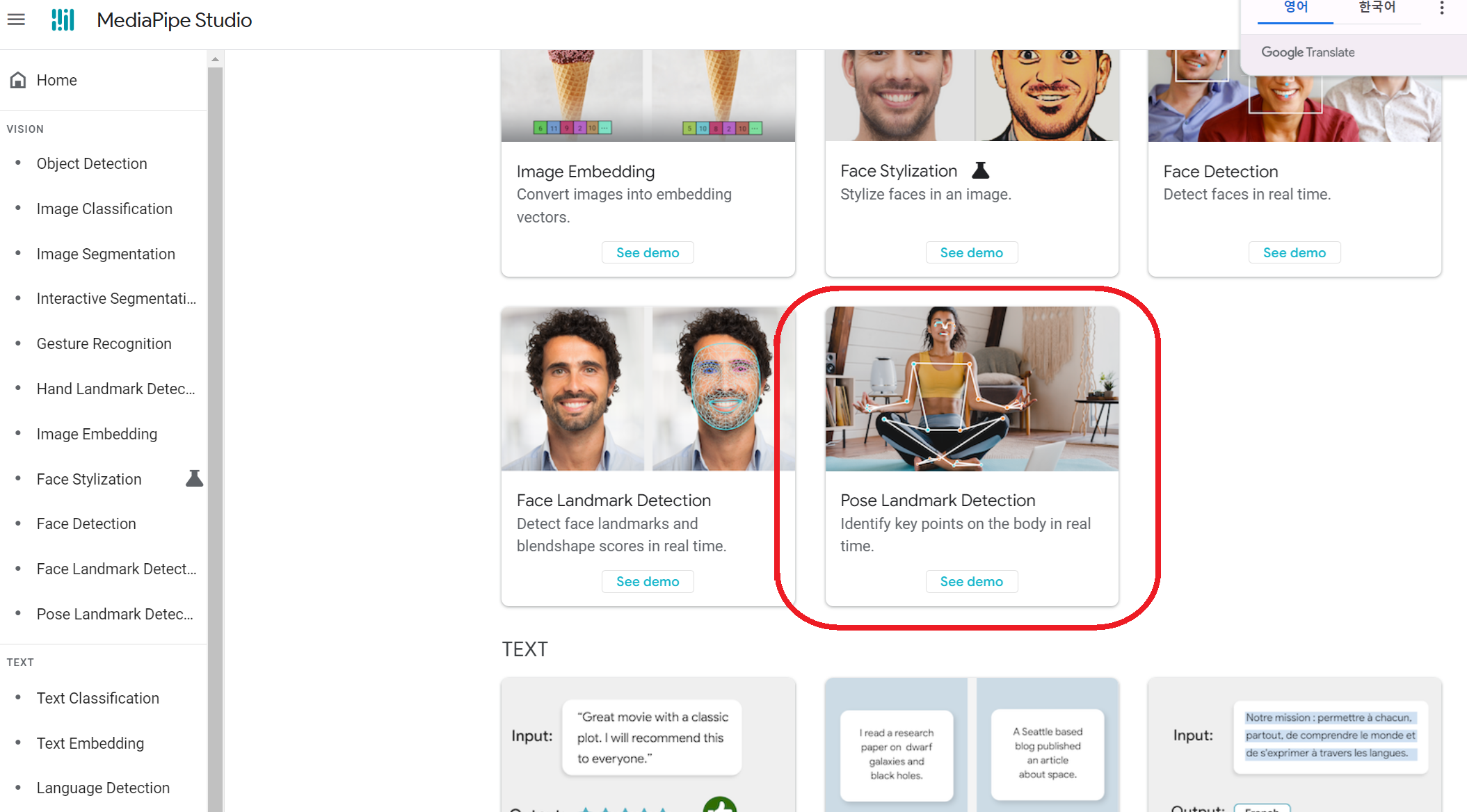
4. 포즈 모델의 활용
- 포즈 모델은 다양한 곳에서 활용될 수 있어요:
- 게임: 플레이어의 움직임을 인식하는 게임 (예: Wii, Kinect).
- 헬스케어: 운동 자세를 교정하거나 피트니스 코칭.
- 안전: 위험한 상황에서 사람의 자세를 감지하여 경고.
https://learnopencv.com/yolov7-pose-vs-mediapipe-in-human-pose-estimation/
YOLOv7 Pose vs MediaPipe in Human Pose Estimation
YOLOv7 Pose is a real time, multi person keypoint detection model capable of giving highly accurate pose estimation results. We compared it with MediaPipe Pose.
learnopencv.com
yolo 모델과 mediapipe 모델 비교
5. 포즈 모델이 어떻게 동작하나요 ?
- 카메라를 통해 실시간으로 영상을 받아들이고, 미디어파이프 포즈 모델이 사람의 신체를 감지하여 각 랜드마크의 위치를 추적합니다.
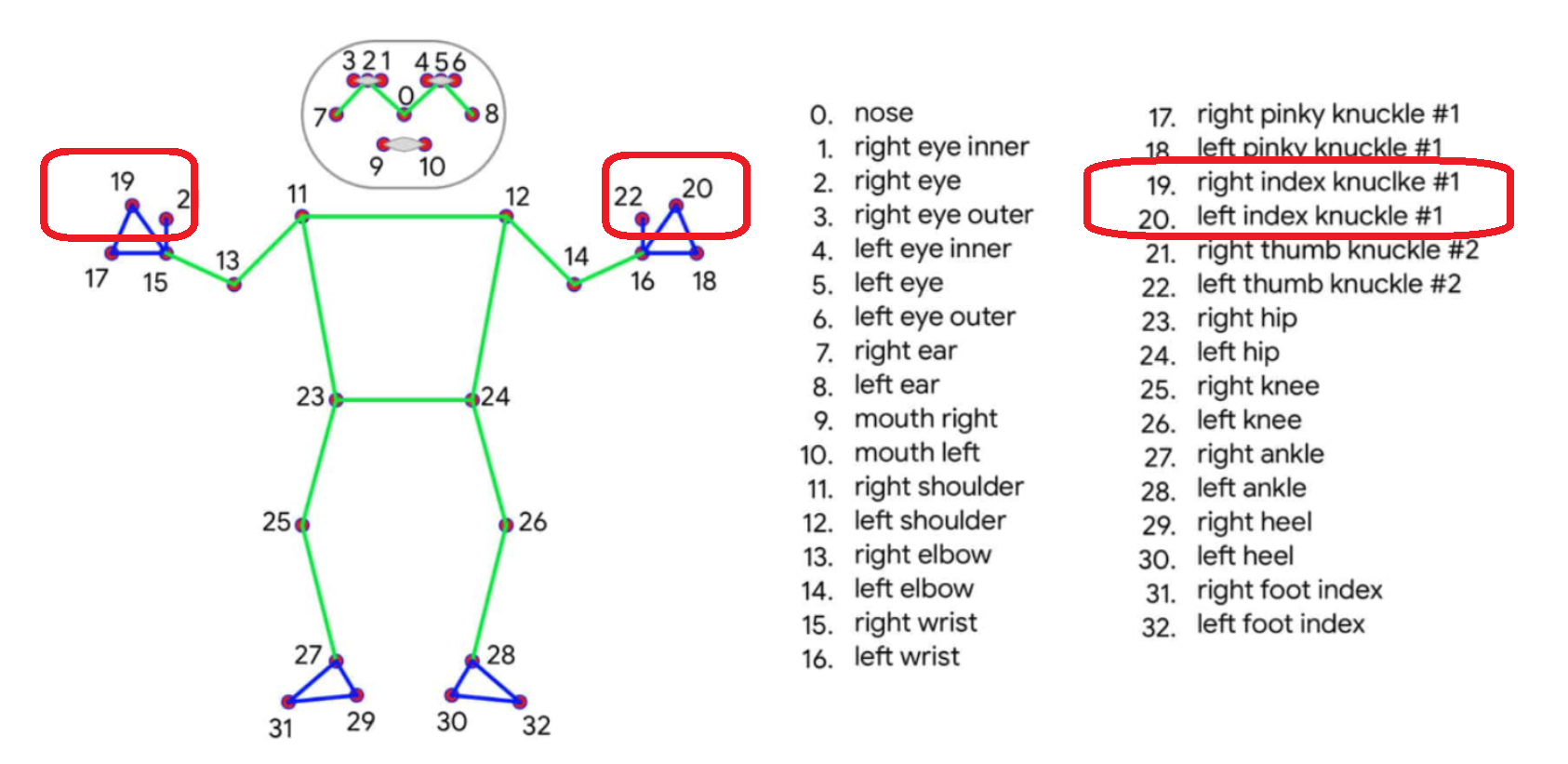
- 모델은 사람의 신체를 33개의 중요한 지점으로 나누어 추적합니다.
- 위 이미지처럼 각 번호는 몸의 특정 부분을 나타내며, 이 정보를 사용해 사람의 움직임을 분석할 수 있어요.

6. 실습: 미디어파이프 포즈 모델 사용해보기
이제 포즈 모델을 직접 체험해 봅시다 ! 파이썬을 사용하여 포즈 모델을 실행하는 간단한 코드를 따라해 보세요.
가상환경을 활성화하여 jupyter lab에서 활용해 보도록 하자.
import cv2
import mediapipe as mp
# 미디어파이프 포즈 모델 로드
mp_drawing = mp.solutions.drawing_utils
mp_pose = mp.solutions.pose
# 웹캠을 열어 실시간으로 영상을 가져옵니다.
cap = cv2.VideoCapture(0)
# 포즈 모델 사용
with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
while cap.isOpened():
success, frame = cap.read()
if not success:
print("카메라로부터 영상을 가져올 수 없습니다.")
continue
# BGR 이미지를 RGB로 변환
frame = cv2.cvtColor(cv2.flip(frame, 1), cv2.COLOR_BGR2RGB)
# 프레임을 포즈 모델에 전달하여 포즈를 처리
results = pose.process(frame)
# RGB 이미지를 다시 BGR로 변환하여 OpenCV에서 사용
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# 포즈 랜드마크가 감지되면 랜드마크와 연결선 그리기
if results.pose_landmarks:
mp_drawing.draw_landmarks(
image=frame,
landmark_list=results.pose_landmarks,
connections=mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing.DrawingSpec(color=(0, 0, 255), thickness=2, circle_radius=2),
connection_drawing_spec=mp_drawing.DrawingSpec(color=(0, 255, 0), thickness=2)
)
# 결과 화면 출력
cv2.imshow('Pose Detection', frame)
# 'q'를 누르면 종료
if cv2.waitKey(1) == ord('q'):
break
# 웹캠을 닫고 모든 창을 닫습니다.
cap.release()
cv2.destroyAllWindows()

7. 실습2: 미디어파이프 포즈 모델 왼손 오른손 좌표 putText() 함수 활용하여 출력해보기
이제 포즈 모델에서 왼손과 오른손 좌표를 풋 텍스트로 출력하는 실습을 진행해 보겠습니다.
우선 랜드마크 번호에 맞춰 x, y, z 좌표를 구할 수 있습니다.
results.pose_landmarks.landmark[19]
results.pose_landmarks.landmark[20]
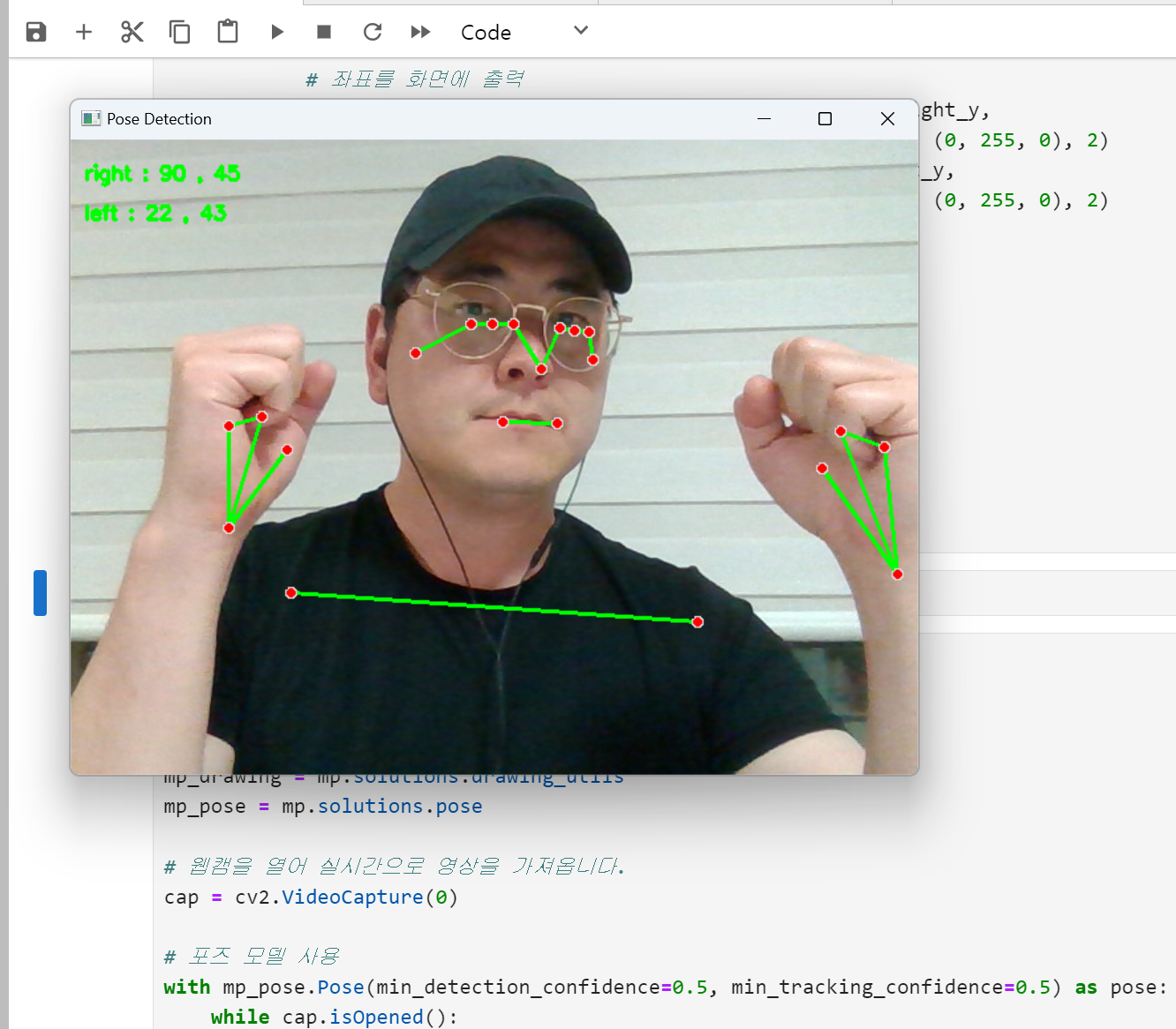
아래 파이썬 코드 이해하기.
# 19번 (오른쪽 검지 첫 번째 마디)와 20번 (왼쪽 검지 첫 번째 마디) 좌표 추출
# 좌표를 100으로 곱하고 정수형으로 변환, 텍스트 변환
right_x = str(int(results.pose_landmarks.landmark[19].x * 100))
right_y = str(int(results.pose_landmarks.landmark[19].y * 100))
left_x = str(int(results.pose_landmarks.landmark[20].x * 100))
left_y = str(int(results.pose_landmarks.landmark[20].y * 100))
# 좌표를 화면에 출력
cv2.putText(frame, "right : " + right_x + " , " + right_y,
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.putText(frame, "left : " + left_x + " , " + left_y,
(10, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
파이썬 코드 아래 위치에 코드 작성하기.

※ 출력된 좌표 확인하기.
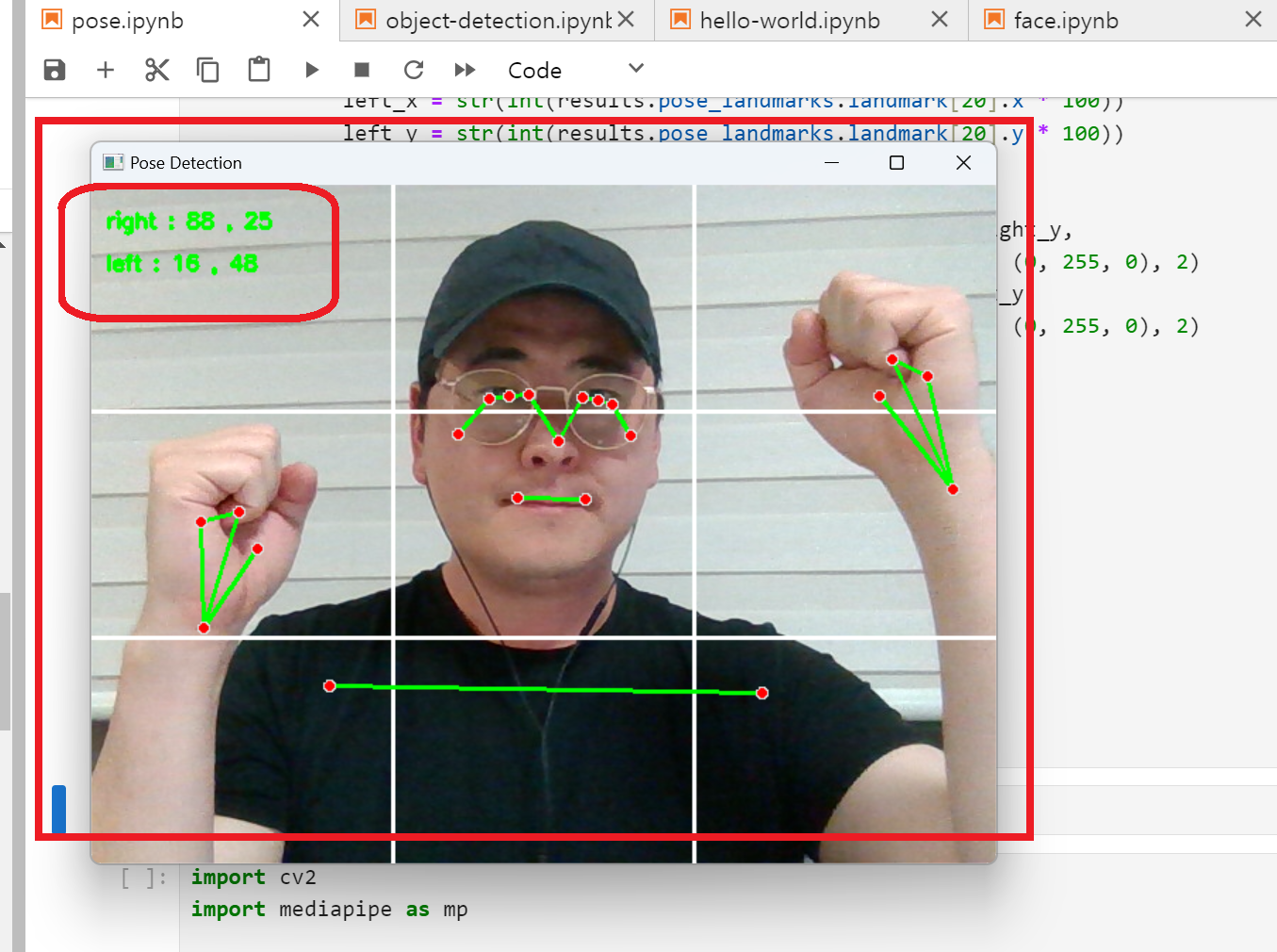
8. cv2.line()함수를 활용하여 아래와 같이 9등분하는 흰색선을 만들어 보자.
아래 링크를 통해 복습하여 아래 사진과 같이 9등분 실선을 만들어 보자.
https://swmakerjun.tistory.com/56
cv2.line() 함수로 선 만들기
1. cv2.line( ) 함수 활용하기. cv2.line(선을 그릴 이미지, 선의 시작 좌표, 선의 끝 좌표, 선의 색상 (b,g,r) , 선굵기 ) # 이미지의 중간에 세로로 흰색 줄을 그립니다. height, width, _ = frame.shape middle_x = widt
swmakerjun.tistory.com
이미지나 비디오 프레임의 크기를 추출
frame.shape는 frame(이미지 또는 비디오 프레임)의 높이(height), 너비(width),
채널 수(RGB 등의 색상 채널)를 반환하는 명령입니다.
height, width, _ = frame.shape
cv2.line(frame, (시작점좌표x,시작점좌표y), (끝점좌표x,끝점좌표y), (255, 255, 255), 2)
'인공지능 기초 수업' 카테고리의 다른 글
| 아두이노 컨베이너벨트 코드 (0) | 2024.10.25 |
|---|---|
| 티처블머신 OpenCV Keras 오픈소스 업그레이드(화면 확장) (5) | 2024.10.24 |
| Miniconda 로 가상환경 만들기. #2 [가상환경 생성과 라이브러리 설치] (2) | 2024.08.24 |
| Miniconda 로 가상환경 만들기. #1 [Miniconda 설치와 실행] (1) | 2024.08.23 |
| math 라이브러리 활용 (1) | 2023.11.28 |


